MongoDB Aggregation Pipelines to Reduce Time of Data Operations
Table of Contents
Recently at Homes.com, one of my coworkers was charged with speeding up a batch process that we were required to run at a scheduled interval. No big deal, but he was stuck: the process required a numberof steps at every typical ‘stage’, for identifying the data we needed to pull, for pulling the data, for transforming the data, and for writing the transformed data back to Mongo.
When he was talking about the process, I realized this would be a perfect use case for Mongo’s aggregation framework. I offered to help, based on my experience with the aggregation framework I got while working on Nasdanq, and immediately got to work on designing an aggregation pipeline to handle this process.
Original Solution#
This batch process exists to update mean and median home value data for a given area. A rough overview is laid out below:
- Query a large collection (> 1 TB) for two fields that help identify an area in which a property resides.
- Join into a single ID
- Use this to pull location data from another collection on a separate database (> 25 GB).
- For each property in this area, we pull from another collection the price.
- These are loaded into an array in our script, and then we iterate to find the mean and median.
At our estimates, if we could run this process to completion with no interruption, it would take ~104 days to finish. This is unacceptable for obvious reasons.
Attempt the First#
We ran into an architecture issue early on. MongoDB’s aggregation pipeline doesn’t support working across multiple databases, and the collections we needed to work on were split between a few databases. Luckily, we were able to move the collections onto a single database so we could start testing the pipeline.
We started with a 9 stage monster - the multiple collections we had to match on required multiple match stages and a stage to perform what was essentially a join. Because the data is stored in memory at each stage, and each stage is limited to 100MB of memory we first attempted to switch on the allowDiskUse option to allow the pipeline to at least run. And run it did. Our DBA team notified us that we were spiking memory usage to unacceptable levels while the pipeline was running.
We reduced the pipeline to 7 stages - we take location data as inputs to the pipeline, match on this to the 25GB collection, use $lookup to join in the 1TB collection holding the ID fields on one of the ID fields, project the fields we actually want, unwind, redact, sort by value, group by location (2 fields), take an average, and sort again. The pipeline looked like this:
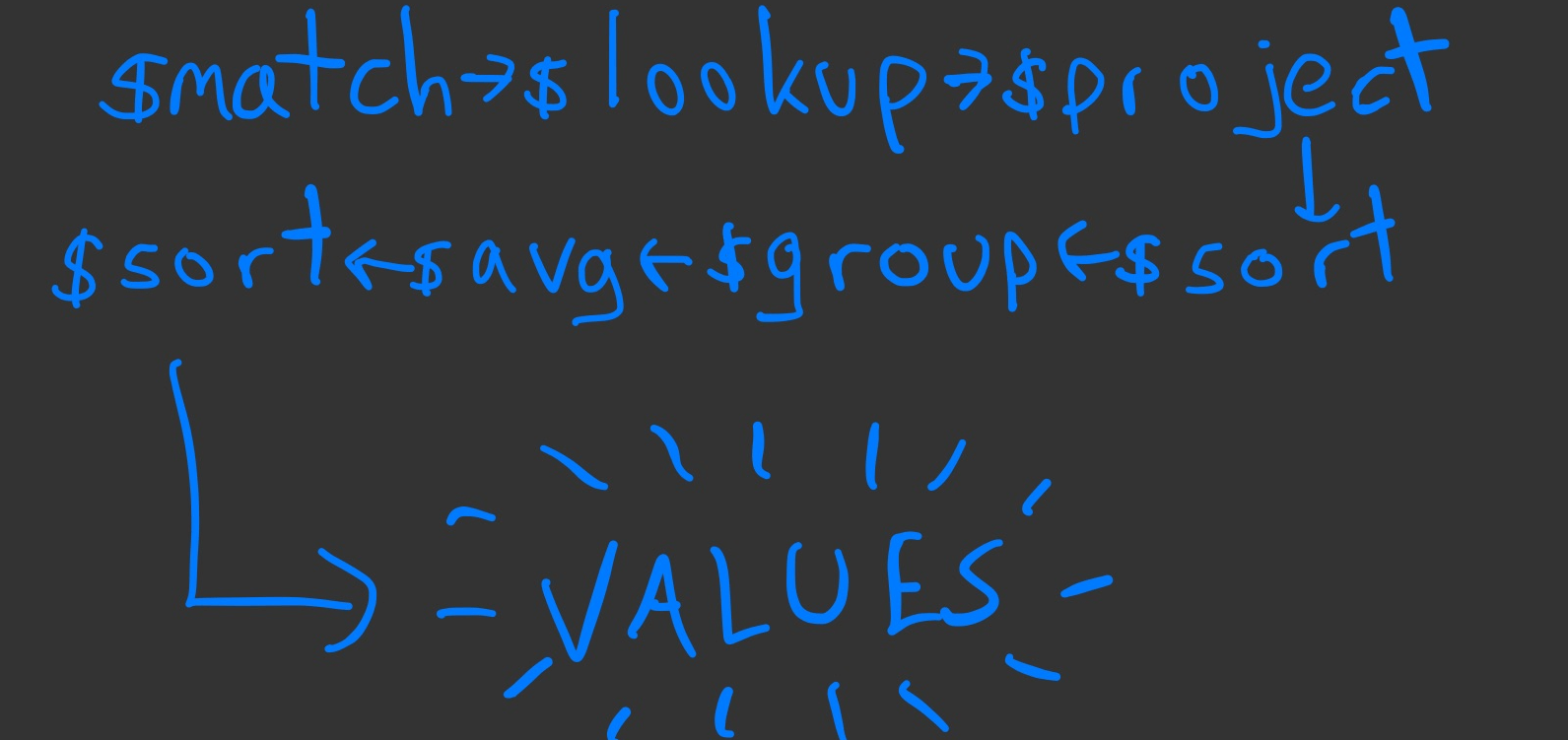
The first iteration of the MongoDB aggregation pipeline
This failed at $lookup. Why? For many locations, we were joining in nearly 1 million documents per month of data, and we wanted multiple years of that data. Across all locations, this fails to solve our performance issues. It also fails to run.
Attempt the Second#
Our first thought was to add the unique identifier (which was a combination of two fields in different collections) to the 1TB collection, but that was not workable due to the size of the collection.
Instead, what we can do is project a concatenated version of the two fields we are using as a UID, use $lookup to join in the 25GB collection on that - because it’s much faster to make this change to the smaller collection. Simultaneously, we were testing performance differences in sorting in our ETL code vs. within the pipeline itself.
Since the time taken in the code to run these sorts was trivial, we could remove these stages from the pipeline. Now we are looking at all IDs for a single month taking 10 days, but we need to run multiple years - this comes out to worse performance than the original solution.
However, an interesting finding was when we ran a single identifier at a time - 1 for one month took about a minute. But one location identifier over 3 years only took 10 minutes. I mention this because it demonstrates how nicely aggregation pipeline performance scales as your dataset grows.
And remember how I said we projected all IDs for one month taking 10 days? In light of the results showing that time taken in the pipeline does not scale linearly with data size, we ran the pipeline and found that a single month for all identifiers took about 14 hours. This is a big improvement, but not enough. So we look for more optimizations.
Attempt the Third#
This was a smaller change, and on its own created a big change in time taken to process our data. We re-architected our data so that we had a temporary collection of a single month of data. We generally process one month at a time, despite the overall length of time we want.
We were able to cut the time in half from the previous attempt - a single month for all identifiers now took only 7 hours and we were now not querying the full 1TB collection when we only wanted a small piece of it anyways. Creating the temporary collections is trivial and done by our counterparts on the DBA team as a part of their data loading procedures.
Attempt the Fourth#
After seeing these results, management was fully convinced of the need of redesigning how we stored this data. Let this be a lesson: hard data is very convincing. So now each month’s data will be in its own collection, when we load data the location data will also be added in to these monthly collections avoiding costly joins via $lookup.
Surprisingly, while testing, adding this information did not impact our overall data preloading times. This location data was also indexed for quicker querying. All of this allowed us to go from a 7-stage aggregation pipeline to 3. Now we start with the split collections, project the fields we are interested (location, value, etc.), group on location, average them and also add all individual values to an array (for sorting and finding the median in code), and output to a temp collection. If we want to process a period of time longer than a month, we rinse and repeat.
For all identifiers in each month, our processing time went from 7 hours to 8 minutes. Then the queries made on the generated collections to get the computed averages plus arrays of individual values to calculate the median in code added a minute per output collection if we did it serially.
Being primarily ETL pipeline builders, we do nothing serially. We tested with 7 workers, and the added processing time goes from a minute to 30 seconds. In production, we have a worker pool that numbers in the hundreds, so this additional time was satisfactory.
If we assume a conservative 7.5 minutes to process a month of data, then projecting to 3 years we estimated we should see runtime of around 4.5 hours. We decided we were happy with this, especially when we considered the original process was projected to take 104 days.
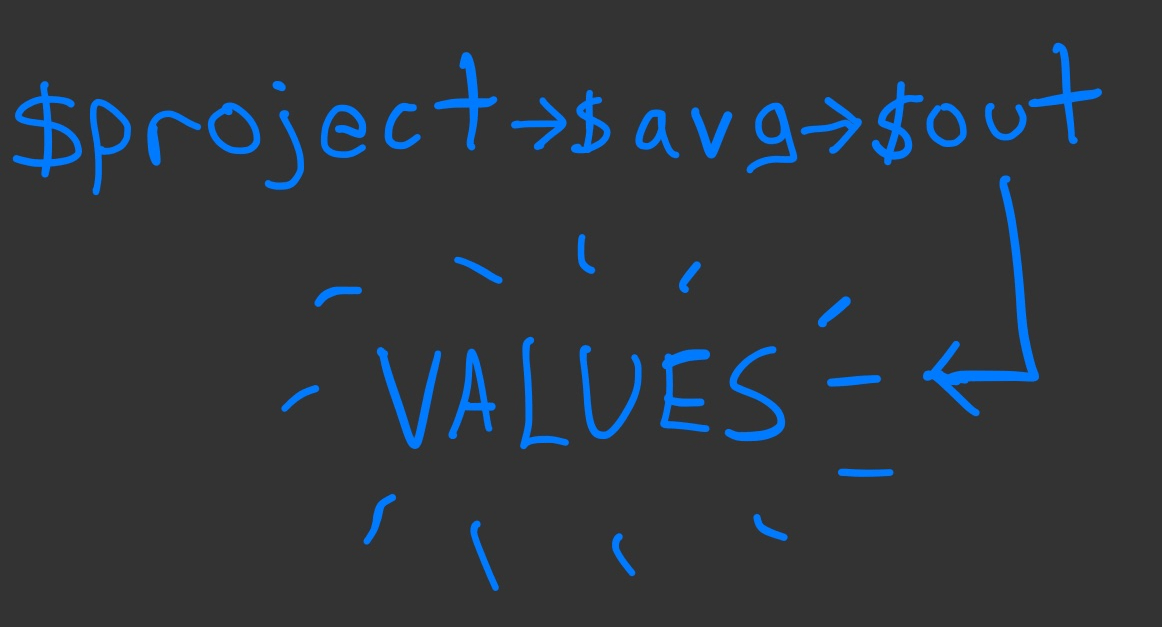
The final iteration of our MongoDB aggregation pipeline
Conclusion#
I learned a lot of lessons from this little project, and wanted to distill them here as a sort of tl;dr to ensure that they can be passed on to the reader.
- Management is convinced by data. Run your proposed changes, show them graphs or numbers of performance improvements. You’re all working to the same goal.
- ABB. Always Be Building. In my case, my work on Nasdanq gave me the knowledge I needed to hear a teammate’s struggles, identify a use case, and implement a plan to alleviate those issues.
- Standups suck, but they’re useful. Hearing my teammate’s struggles with this code during a standup meeting allowed me to assist him and come up with a workable solution.
- More generally, communication is important. Not only was understanding my teammate’s needs important, but this project required constant contact between our DBA team, me and my teammate (who was running many of our tests), and management of our team, the DBA team, and the larger team we report to.
- And, finally, MongoDB’s aggregation pipelines are incredibly powerful. They’re worth learning and getting familiar with if you work with sizable datasets at all.